In a world full of microservices and distributed systems, building robust and reliable APIs is of paramount concern. One key concept that plays a vital role in achieving reliability is idempotency.
In this article, we'll delve into the world of idempotency, exploring what it is, why it's important, and how it can be implemented to solve the persistent problem of duplicate processing in APIs. Along the way, we'll see how to build an idempotent API in Node.js with Redis.
What We'll Cover
Here's what we'll talk about in this post:
- What is idempotency?
- Why idempotency is important
- Idempotent HTTP methods
- A duplicate processing problem using a sample Node.js API
- Adding idempotency to sequential requests in Node.js
- Idempotency for parallel duplicate requests in Node.js
- Real-world applications
You can see all the code used in this post on GitHub.
What Is Idempotency?
An operation is considered idempotent if applying it multiple times has the same effect as applying it once. In a REST API, that means performing multiple HTTP requests should have the same outcome (not output) as that of a single HTTP request.
Why Idempotency Is Important
Idempotency is a crucial ingredient in building reliable and scalable APIs. While it might be acceptable to have an API that's not idempotent for a personal project, it's a red flag in the context of a distributed system.
In a typical distributed system, various services interact with each other. To complete an operation, a request has to pass through multiple stages, potentially encountering network issues, disk failures, delays in scaling up, or even the occasional service going offline. In such complex scenarios, it's almost certain that requests will need to be retried at some point.
This is where having idempotent operations is absolutely crucial. For retries to work successfully, all operations must adhere to the principle of idempotency. Retrying requests should not produce incorrect or unintended results.
Idempotent HTTP Methods
Some HTTP methods are idempotent by default. For example, fetching details for a resource using the GET method is idempotent because it'll always give the same result for a given input. Similarly, the following methods are also idempotent:
- HEAD
- OPTIONS
- TRACE
- PUT
- DELETE
Note that the last two methods (PUT and DELETE) are idempotent but unsafe. A safe HTTP method cannot alter the state of resources on the server side. To summarize:
- All safe HTTP methods are idempotent.
- PUT and DELETE are idempotent, but unsafe since they can alter the server state.
This leaves us with POST and PATCH HTTP methods, which are non-idempotent. We will learn how to make these methods idempotent in the coming sections.
A Duplicate Processing Problem Using a Sample Node.js API
A request can fail due to network partitions, disk failures, timeouts, throttling, or DNS lookup issues. There are a lot of real-world scenarios where idempotency helps. Let's zip through a few:
- Websites typically show a “please wait, already processing” popup when you accidentally double-click or try to leave a page while it's processing your request.
- Clicking on the elevator button multiple times doesn't change its behavior. The elevator still goes to the desired floor.
- Wishlisting an item that's already been added to your wishlist on Amazon simply brings that item to the top of your wishlist, but it still holds the same items.
The applications of idempotency are not just limited to one use case. This is precisely why it's such a valuable concept to learn as a developer. It's language agnostic, so there are no barriers to entry.
To understand the problem and get to a working solution, our journey will include a sample Node.js API 👇:
async function create(req, res) { try { const { longURL } = req.body; // New long URL, generates a new and unique slug const slug = await urlService.generateNewSlug(); // save short URL <> long URL mapping to the database await urlService.saveToDB(slug, longURL); // Return the newly generated short slug return res.status(HTTP_STATUS_CODES.SUCCESS).json({ status: true, message: "Short slug created successfully", data: { slug }, }); } catch (err) { return res.status(HTTP_STATUS_CODES.INTERNAL_SERVER_ERROR).json({ status: false, message: "Could not create short slug", error: err, }); } }
It creates a new short slug for every long URL passed to it and saves it into the database. Let's give it a run:
{ "status": true, "message": "Short slug created successfully", "data": { "slug": "UfBHWg" } }
This is functional but has two flaws. We'll uncover them in the next sections.
Adding Idempotency to Sequential Requests in Node.js
Our current API implementation returns a different short slug every time you request the same long URL. Not only is this redundant, but it's a waste of CPU and storage resources. We need to ensure that there's only one short slug present for a given long URL at any point in time.
To achieve idempotency, we can leverage our saved mappings in the database. For a given long URL, we can check if a slug exists and return early if that's the case.
Here's the updated code that generates a short slug:
async function create(req, res) { try { const { longURL } = req.body; // Check if the mapping already exists const mapping = await service.urlService.findByLongURL(longURL); if (mapping) { return res.status(HTTP_STATUS_CODES.SUCCESS).json({ status: true, message: "Short slug created successfully", data: { slug: mapping.slug }, }); } // New long URL, generates a new and unique slug const slug = await urlService.generateNewSlug(); // save short URL <> long URL mapping to the database await urlService.saveToDB(slug, longURL); // Return the newly generated short slug return res.status(HTTP_STATUS_CODES.SUCCESS).json({ status: true, message: "Short slug created successfully", data: { slug }, }); } catch (err) { return res.status(HTTP_STATUS_CODES.INTERNAL_SERVER_ERROR).json({ status: false, message: "Could not create short slug", error: err, }); } }
Note that we now check for the mapping in our database before generating a new slug. If the mapping exists, we return the stored slug. Otherwise, we generate a new one (and store that in the database).
This ensures we're processing a long URL only once.
Problem solved. But is it?
Idempotency doesn't mandate the same API response for every duplicate request. For instance, when using a create API, the initial request might return a 200 status code, while a subsequent duplicate request could instead return a 202 status code and not create the resource again. Even though the response differs, the API's behavior remains idempotent.
Idempotency for Parallel Duplicate Requests in Node.js
Let's fire multiple requests to our short slug generator in parallel. Here's our script:
const async = require("async"); const axios = require("axios"); const payload = { method: "post", url: `http://localhost:8201/url/create`, headers: { "Content-Type": "application/json" }, data: { longURL: "http://example.com/100", }, }; function shortenURL(reqPayload) { return axios(reqPayload).then((resp) => { return resp.data; }); } async.parallel( [ function (callback) { return shortenURL(payload) .then((res) => { console.log("res1: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 1 = ", err.message)); }, function (callback) { payload.data.num += 1; return shortenURL(payload) .then((res) => { console.log("res2: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 2 = ", err.message)); }, function (callback) { payload.data.num += 1; return shortenURL(payload) .then((res) => { console.log("res3: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 3 = ", err.message)); }, function (callback) { payload.data.num += 1; return shortenURL(payload) .then((res) => { console.log("res4: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 4 = ", err.message)); }, function (callback) { payload.data.num += 1; return shortenURL(payload) .then((res) => { console.log("res5: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 5 = ", err.message)); }, function (callback) { payload.data.num += 1; return shortenURL(payload) .then((res) => { console.log("res6: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 6 = ", err.message)); }, function (callback) { payload.data.num += 1; return shortenURL(payload) .then((res) => { console.log("res7: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 7 = ", err.message)); }, function (callback) { payload.data.num += 1; return shortenURL(payload) .then((res) => { console.log("res8: ", res.data.slug); callback(null, res.data.slug); }) .catch((err) => console.log("err 8 = ", err.message)); }, ], (err, results) => { if (err) { console.log("Final error: ", err.message); } else { console.log("results: ", results); } } );
And here's the output when we run the above script:
results: ['s9SW7p', 's9SW7p', 's9SW7p', 'el42vA', 'TswIY7', 'aFwbK7', 'AYcaBM', 'gU6fP8']
Our barebones API isn't faring well when hit with a couple of parallel duplicate requests. Even when the requests are precisely the same, the output is different. We need to ensure that parallel duplicate requests do not cause unintended side effects due to a Node.js context switch.
Welcome, locks!
Distributed locks are crucial in environments where different processes or clients have access to shared resources. In such environments, locks are used to prevent race conditions — scenarios where two or more operations access a shared resource and attempt to modify it simultaneously, leading to unpredictable outcomes. Our API faces such challenges when parallel duplicate requests are executed. By setting an exclusive lock, we ensure that only one request can be processed at a time.
We'll implement an exclusive lock mechanism using Redlock (Redis Lock) in our API. Redlock is a distributed locking solution that helps prevent the concurrent execution of code blocks by different processes.
Since race conditions happen only when parallel duplicate requests are fired, we can set an exclusive lock in the control flow to allow only one request at a time. It's important to understand that two duplicate requests can be processed, but not at the exact same time.
Let's acquire an exclusive lock using Redlock at the entry point:
async function create(req, res) { let lock; try { // Try to acquire the lock lock = await service.urlService.acquireLock( "URL:CREATE:ExclusiveLock", 100 ); const { longURL } = req.body; // Check if the mapping already exists const mapping = await service.urlService.findByLongURL(longURL); if (mapping) { return res.status(HTTP_STATUS_CODES.SUCCESS).json({ status: true, message: "Short slug created successfully", data: { slug: mapping.slug }, }); } // New long URL, generate a new and unique slug const slug = service.urlService.generateNewSlug(); // save short URL <> long URL mapping to the database await service.urlService.saveToDB(slug, longURL); // Return the newly generated short slug return res.status(HTTP_STATUS_CODES.SUCCESS).json({ status: true, message: "Short slug created successfully", data: { slug }, }); } catch (err) { return res.status(HTTP_STATUS_CODES.INTERNAL_SERVER_ERROR).json({ status: false, message: "Could not create short slug", error: err, }); } finally { /** * Manually release the lock when the operation is complete * * NOTE: Redlock's release method is not a no-op, it throws an error if you try to release an already expired lock ([more here](https://github.com/mike-marcacci/node-redlock/issues/168#issuecomment-1165700540)). Setting a small TTL usually triggers this unexpected behavior. * As a workaround, we're ignoring the errors from lock.release() */ if (lock) await lock.release().catch(() => {}); } }
Now, each request initially attempts to acquire an exclusive lock. If it's unsuccessful, the request is rejected, resulting in a lock acquisition error. Here's how the output appears when running the same script, which sends parallel duplicate requests:
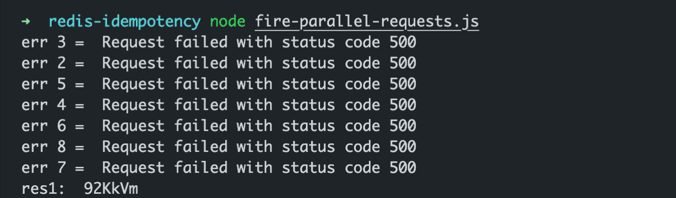
As expected, only one of those 8 parallel duplicate requests can generate a slug. The others fail during the lock acquisition stage. We have finally made our random slug generator truly idempotent.
Real-World Applications
What I find appealing about idempotency is its versatility. You'll notice it being applied in different situations and technologies, regardless of the tools used. As I mentioned earlier, it's actually quite commonly employed in:
- Cases where achieving a one-time action is crucial, such as in transactional systems like banks and stock exchanges.
- Various GitOps tools like ArgoCD, where reapplying the same configuration doesn't lead to redundant deployments.
- Working with React.js, because setting the same state doesn't re-render a component.
- Sound financial systems, so they don't suffer from double payment issues where the customer is accidentally charged twice.
Wrapping Up
In this article, we learned what idempotency is, how it can prevent duplicate processing problems, and how to use it in your Node.js application. You now have one more tool at your disposal to build better APIs.
Happy coding!
P.S. If you liked this post, subscribe to our JavaScript Sorcery list for a monthly deep dive into more magical JavaScript tips and tricks.
P.P.S. If you need an APM for your Node.js app, go and check out the AppSignal APM for Node.js.