

Today, non-relational, schemaless data models dominate the domain of databases. Non-relational databases are more developer-friendly and scale better than the relational databases of the past. However, it is harder for them to do complex tasks.
Now we have a new player in the game to address this issue: EdgeDB. EdgeDB is built on top of PostgreSQL and introduces a new conceptual model for representing data.
But before we dive into what EdgeDB is, how it compares to SQL and ORM, and how to create a Node.js app with EdgeDB, let's take a quick look at relational databases.
What is a Relational Database?
The relational database originated in the 1970s, as IBM and Oracle took initial steps towards the concept of database tiers in applications. IBM adopted Structured Query Language, and later it became a de facto standard for relational databases.
Even though relational databases and SQL were standard database systems, they got a lot of criticism. SQL was accused of being:
- A large language
- Hard to compose
- Inconsistent in syntax and semantics
- Difficult to integrate well enough with an application language
EdgeDB fixes some of these issues.
What is EdgeDB?
EdgeDB is the first open-source, graph-relational database designed as the successor to SQL and the relational paradigm.
EdgeDB uses the Graph Relational Model, where data is described and stored as strongly typed objects, and relationships link through objects.
It uses PostgreSQL under the hood, inheriting all the power of a relational database. EdgeDB stores and queries data using relational database techniques and requires a strict schema design.
What is a Graph Relational Model?
The graph-relational model is built on top of the relational model, with some additional features. This new model helps EdgeDB overcome the conceptual and technical difficulties often encountered when a relational database is used in an application (object-relational impedance mismatch). EdgeDB also has the solid basis and performance of a relational database.
Let’s look at some terminology to understand the graph-relational model better.
| Relational Model | Graph Relational Model |
|---|---|
| Table | Object type |
| Column | Property/link |
| Row | Object |
Graph-relational databases extend the capabilities of an object-relational database in three main ways:
-
Object unique identity
All data objects are globally unique, immutable identifiers. So you don't have to specifically add Ids to your schemas. EdgeDB has a constraint that adds a unique id (UUID) upon insertion.
-
Object links
In a relational model, an attribute will have a specific set of primitive data types, and relationships are built via these attributes with foreign key constraints. But in the graph-relational model, objects have primitive data types and direct references to other objects (links). So you don't need to mess around with primary keys, foreign keys, and table joins. Objects are unique, with links to represent their relationships.
-
Cardinality
Cardinality specifies the number of values assigned to an attribute.
In a traditional relational model, an attribute will only have a name and datatype, but a graph-relational model comes with this third component called cardinality. Cardinality has five different enums:
Empty,One,AtMostOne,AtLeastOne, andMany.
What Does EdgeDB Aim to Solve?
The goal of EdgeDB is to solve the hard design problems of relational models. EdgeDB performs better in modern SQL tasks like subqueries, advanced aggregation, and window functions, while adhering to ACID properties, performance, and reliability.
Features of EdgeDB
Let's look at some of EdgeDB's features to see why it stands out:
- A declarative schema lets you express inheritance, computed properties, functions, complex constraints, and access controls.
- A migration system that automatically detects changes and compares diff in schemas.
- A rich-typed system with a native JavaScript/TypeScript query builder.
- A query language called EdgeQL.
- Support for several languages like Python, JavaScript/TypeScript/Deno, and Go.
- Provides a CLI tool beyond the REPL, allowing users to install, create, handle migrations, and manage databases locally (and soon in the cloud).
EdgeDB Vs. SQL and ORM
Both Structured Query Language (SQL) and Object Relational Mapping (ORM) have their strengths and weaknesses. Let's see how EdgeDB fares against them in some key aspects:
-
Schema representation
EdgeDB has a declarative schema language to represent schemas. It uses .esdl files to define a schema, which is much easier to manage when compared with DDL used in SQL.
-
Migrations
With EdgeDB, migrations (.edgeql files) are created through the CLI. EdgeDB has an inbuilt system that compares schema changes with the current database. Therefore, it's much easier to manage migrations.
-
Query syntax
EdgeDB is built to address some of SQL’s most unintuitive design aspects, like eliminating joins. EdgeQL has better composability or ability to write nested statements with a lesser learning curve.
-
Result structure
The structure of results from a traditional SQL query is a list of scalar-valued tuples. You need to convert this to objects to use the data in your application, which requires some additional steps to your application logic. Both ORM and EdgeQL return structured objects as results of executing queries.
-
Language integration
With EdgeQL, you can write queries using plain strings. Its inbuilt query builder enables you to write EdgeQL queries with syntax highlighting, autocompletion, and auto-formatting.
-
Performance
With EdgeDB, your EdgeQL compiles with optimized PostgreSQL queries. Queries will execute in a single excursion.
EdgeQL identifies JOIN-heavy queries and converts them to a set of subqueries, before finally aggregating the results. The performance of EdgeQL compared to SQL and ORM is also much better.
-
Power
EdgeDB schema definitions and the EdgeQL language are bound together, so your schema types can have computed fields, indexes, and constraints that resemble complex EdgeQL expressions. This makes EdgeDB a powerful solution.
Architecture of EdgeDB
EdgeDB consists of a three-layer architecture: the client, server, and PostgreSQL server.
Between the client and EdgeDB server, we have the EdgeDB binary protocol layer, which inherits some properties of the Postgres binary protocol.
It will serialize EdgeQL data before moving toward the EdgeDB server. Then the serialized EdgeQL data will be parsed, compiled into SQL, and executed on the PostgreSQL server.
The EdgeDB server has an in-memory cache that caches compiled queries and prepared statements, and reduces database load when those queries execute. It uses the Postgres native binary protocol, which allows the EdgeDB server to communicate with the PostgreSQL server.
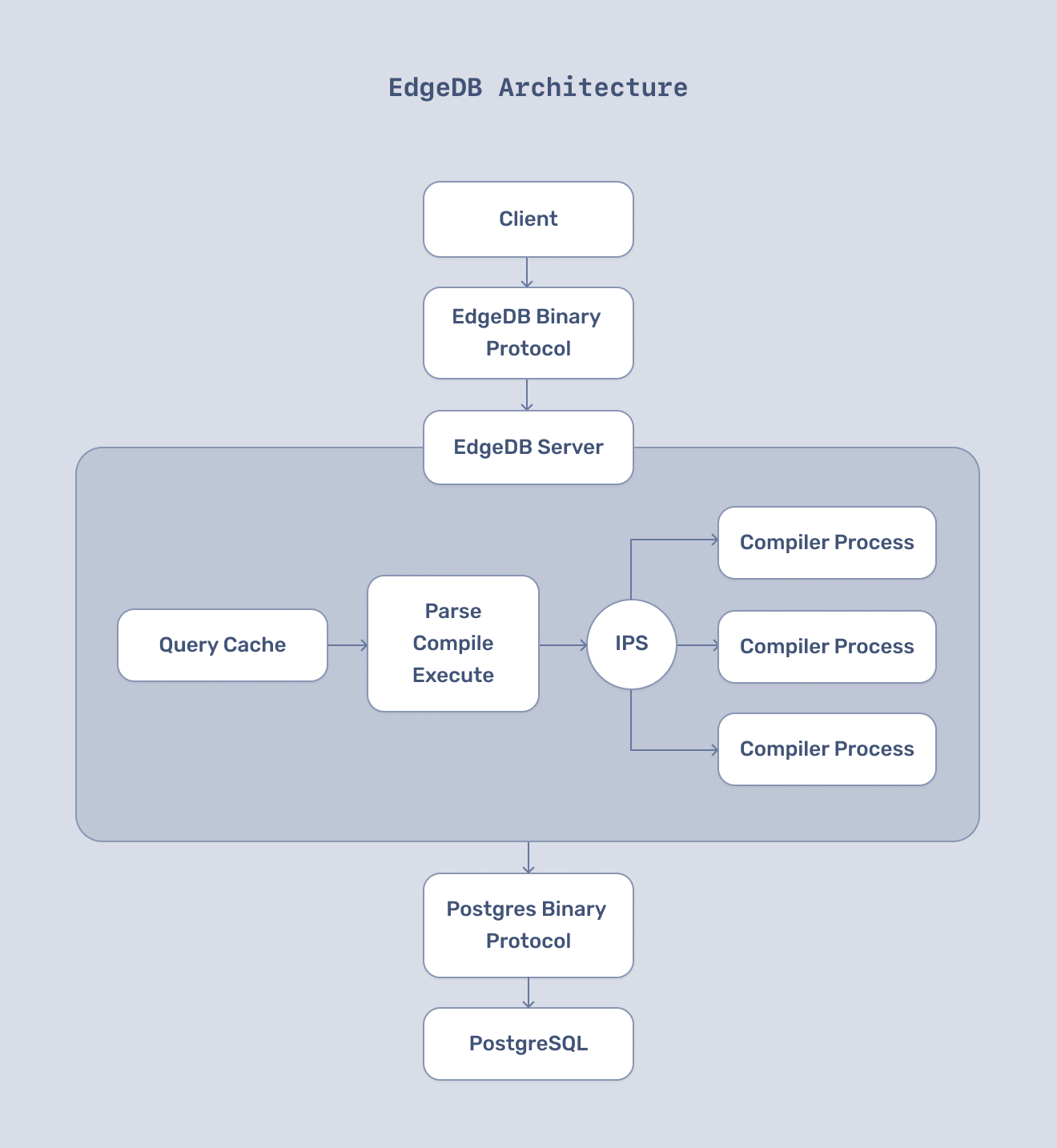
Original image source: https://i.imgur.com/5DQjd7U.png
The EdgeDB core and server are written in Python, along with some Rust extensions to make execution fast.
Hands-on Project: Build a Node.js App with EdgeDB
Let's get our hands dirty by building an application with EdgeDB. For this demonstration, we'll create a small Pokémon REST API.
First, install EdgeDB and initialize the REST API project.
Installing EdgeDB
EdgeDB supports the three major platforms (Windows, Mac, and Linux).
We will be using Windows in this example. Execute the following command in a PowerShell terminal:
$ iwr https://ps1.edgedb.com -useb | iex
For macOS and Linux, use:
$ curl https://sh.edgedb.com --proto '=https' -sSf1 | sh
Initialize the Node.js Project
Now let's create a directory and initialize the Node project inside it.
$ mkdir edge-pokemon $ cd edge-pokemon $ npm init -y
Install dependencies. Since we are creating a REST API using Node, we will use the Express framework.
$ npm install express edgedb dotenv cors $ npm install typescript concurrently nodemon @types/cors @types/express @types/node --save-dev
Since we are using TypeScript, let's define the TypeScript configuration file tsconfig.json. Generate it using the following command:
$ npx tsc --init
Now, let's add the attribute "outDir": "./dist" to the tsconfig.json file (where ./dist is the directory that holds the compiled code).
Initialize the EdgeDB instance.
$ edgedb project init
The above command will create an edgedb.toml file and dbschema directory, which holds the schema, migrations, and configurations for your EdgeDB instances.
Add the Schema to Your Node.js App
Now let's create our schema. Navigate to the default schema file under dbschema/default.esdl.
module default { scalar type Result extending enum<Won, Lost, Tie>; type Pokemon { required property name -> str; required property description -> str; property height -> int64; property weight -> int64; } type Battle { property result -> Result; required link contender -> Pokemon; required link opponent -> Pokemon; } }
Notice that we are not adding an id field, primary, or foreign keys here. Instead, we have built the relationship between Pokémon and Battle through the link. Each Battle object will have a link or relationship to a pokémon via the properties contender and opponent.
Now we'll build a migration file based on our schema.
$ edgedb migration create
This will generate a migration file under dbschema/migrations/<migration_number>.esdl, consisting of an EdgeQL query with some DDL commands like CREATE TYPE, CREATE PROPERTY, CREATE LINK. Run the migration using the following command.
$ edgedb migrate
Two objects will be generated — Pokémon and Battle. You can run the command edgedb list types to confirm this.
Now we can start to code our application's server. But first, let's use the query builder in our project for a code-first way to write fully-typed EdgeQL queries with TypeScript.
$ npx edgeql-js
Based on our schema, this will generate some types and JavaScript/TypeScript bindings for our EdgeDB instance under the directory dbschema/edgeql-js/.
Create the Express server by making a file called index.ts under the project's root.
import express, { Express, Request, Response } from "express"; import dotenv from "dotenv"; dotenv.config(); import cors from "cors"; const app: Express = express(); const port = process.env.APP_PORT || 3000; app.use(cors()); app.use(express.json()); app.use(express.urlencoded({ extended: true })); app.listen(port, () => { console.log(`[server]: Server is running at https://localhost:${port}`); });
Define the endpoints and write queries with edgeql-js inside them. Let's start with the /pokemon and /pokemons endpoints.
import * as edgedb from "edgedb"; import e from "./dbschema/edgeql-js"; const client = edgedb.createClient(); // initialize the EdgeDB connection app.post("/pokemon", async (req: Request, res: Response) => { try { const query = e.insert(e.Pokemon, { name: req.body.name, description: req.body.description, height: req.body.height, weight: req.body.weight, }); const result = await query.run(client); res.status(200).send(result); } catch (error) { console.error(error); res.status(500).send(error); } });
In the above endpoint, you'll notice that we created a query object via edgeql-js by passing some parameters from the request object.
When you execute the above query, the data will persist under the Pokémon object type.
app.get("/pokemons", async (_req: Request, res: Response) => { try { const query = e.select(e.Pokemon, (pokemon: any) => ({ id: true, name: true, description: true, height: true, weight: true, })); const result = await query.run(client); res.status(200).send(result); } catch (error) { console.error(error); res.status(500).send(error); } });
Here, we have written a query and selected some attributes or properties. You can pass attributes or properties along with boolean values to populate them.
Now let's move on to the special endpoints /battle and /battles, which deal with links (relationships with Pokémon objects).
app.post("/battle", async (req: Request, res: Response) => { try { const query = e.insert(e.Battle, { contender: e.select(e.Pokemon, (pokemon) => ({ filter: e.op(pokemon.id, "=", e.uuid(req.body.contender_id)), })), opponent: e.select(e.Pokemon, (pokemon) => ({ filter: e.op(pokemon.id, "=", e.uuid(req.body.opponent_id)), })), result: req.body.result, }); const result = await query.run(client); res.status(200).send(result); } catch (error) { console.error(error); res.status(500).send(error); } });
We have some nested queries written for contender and opponent attributes that retrieve the Pokémon object. These Pokémon objects are used to make the relationship or link between the Pokémon and the Battle object types.
app.get("/battles", async (_req: Request, res: Response) => { try { const query = e.select(e.Battle, (battle: any) => ({ id: true, contender: { name: true }, opponent: { name: true }, result: true, })); const result = await query.run(client); res.status(200).send(result); } catch (error) { console.error(error); res.status(500).send(error); } });
We use a select query in the above endpoint to fetch and populate the links data (relationships). Notice that we pass the values name: true for the contender and opponent attributes, which will fetch the name of the pokémon linked to the battle objects. In this manner, you can write type-safe queries with edgeql-js.
Now we can execute these queries through our Express application. But first, let's add some scripts under the scripts section of our package.json file.
"scripts": { "build": "npx tsc", "start": "node dist/index.js", "dev": "concurrently \"npx tsc --watch\" \"nodemon -q dist/index.js\"" },
Note that there are some special keywords (tools) like concurrently and nodemon in the dev script. These tools come in handy in the development phase. They allow us to execute several commands concurrently and automatically restart our application when a file change is detected in our project.
The build script will compile our TypeScript code to ES6 (based on the target attribute under compilerOptions in the tsconfig.json file). The start command begins the compiled version of the Express application.
Let's start the development server by executing the following script on the terminal from the project root directory.
$ npm run dev
This will start the Express project on http://localhost:3000. Test this application using Postman, a tool that allows us to test API endpoints.
Note: When you start the project for the first time, you might face a MODULE_NOT_FOUND error (Cannot find module '/path/to/project/edge-pokemon/index.js'). This is because the build folder or ./dist has not yet been generated. You can avoid this by running build before start, or running start again.
First, we'll test /pokemon, which will create or save a pokémon. This is a POST endpoint, so we need to send body data in x-www-form-urlencoded form. Now add the parameters name, description, height, and weight.
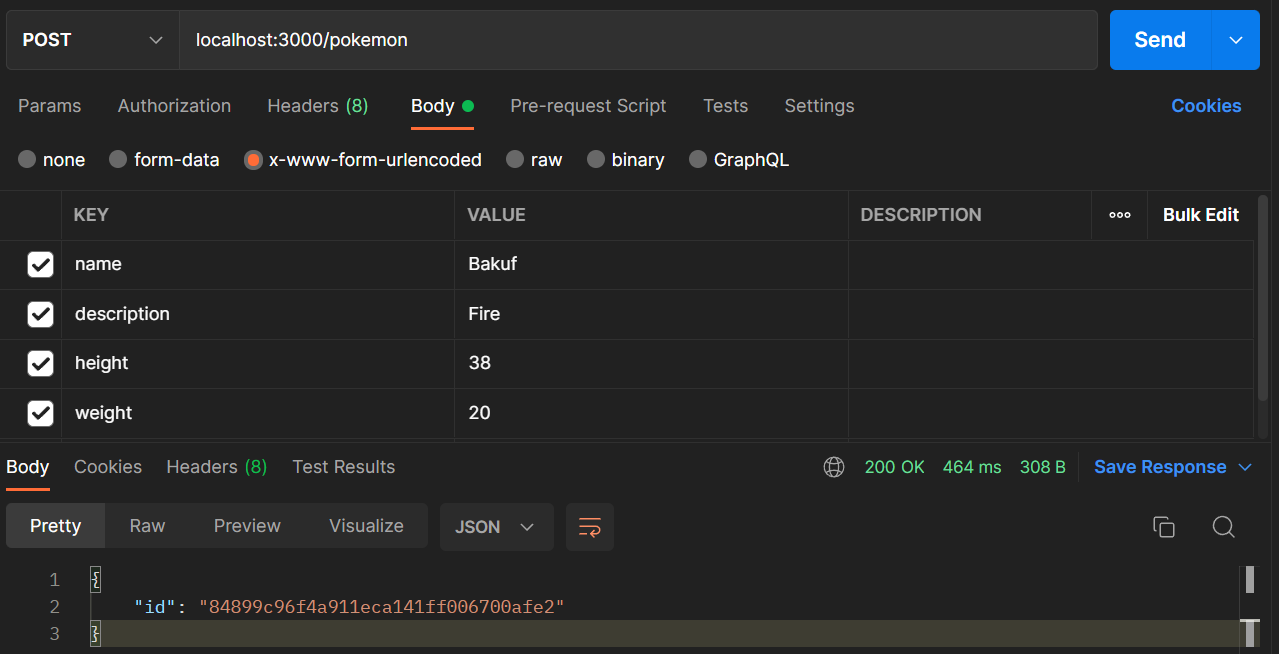
When you test this endpoint, you will notice a unique id of a pokémon object is returned as the response. This is the default behavior of EdgeDB's insert API.
Next, let's test the /pokemons, which will return all pokémon created. This is a GET endpoint, so you will need to send a GET request to fetch data. You don't need to pass any parameters for this endpoint.
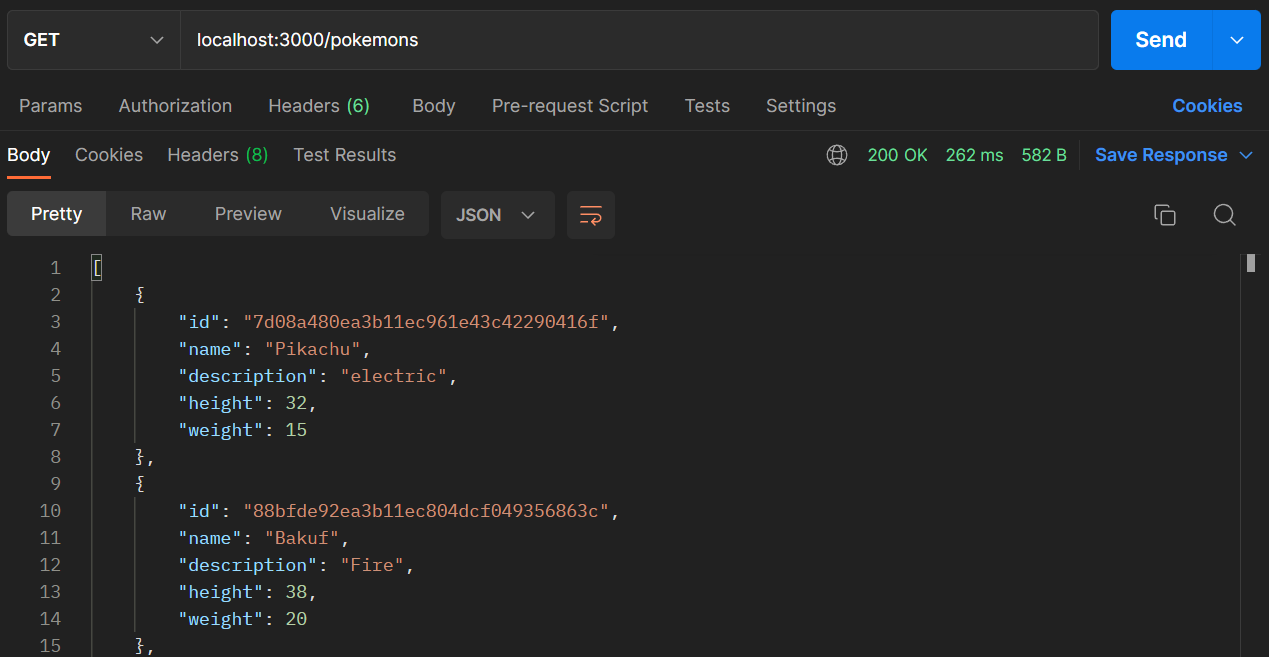
This endpoint will send an array of pokémon data as the response.
Test the /battle endpoint where you will have to make a POST request to create a battle. For this, pass the parameters contender_id (pokémon id), opponent_id (pokémon id), and result (only one out of the string values Won, Lost, Tie).
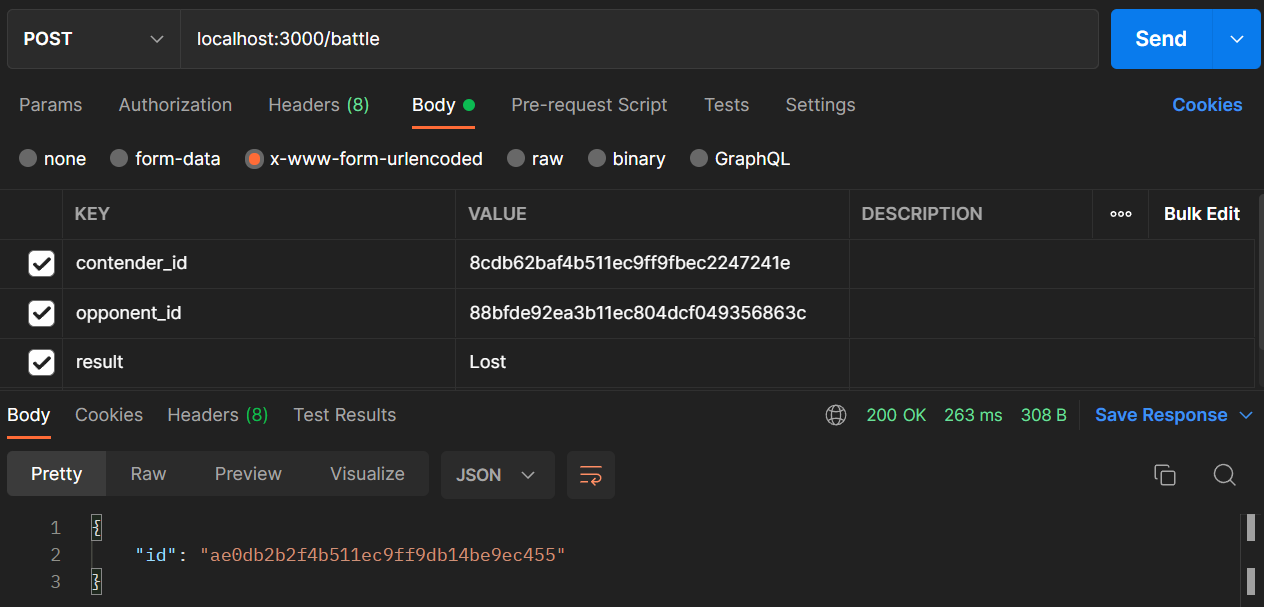
This endpoint will also return an id, the unique id for a battle object.
Finally, retrieve some battles by making a GET request to the /battles endpoint.
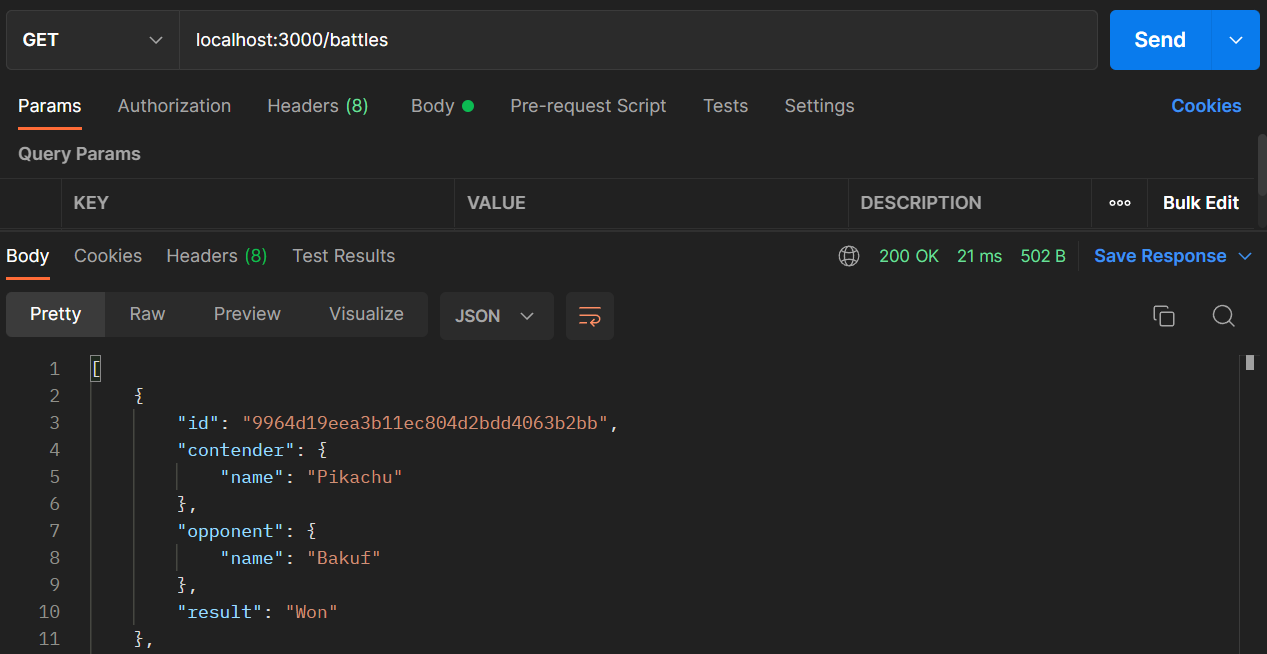
This endpoint will send an array of pokémon battle data as the response.
You can find the complete code for this in my GitHub repo. Feel free to clone the repo, play around with the demo project, and see how EdgeDB works.
Wrap Up and Next Steps
In this post, we built a Node.js app using EdgeDB. We explored EdgeDB's cool features — its rich-typed system, feature-rich CLI, and good migration tool. We saw how EdgeDB supports major programming languages and gives great performance.
Version 1.0 of EdgeDB was recently released, and the roadmap towards version 2.0 looks promising. You can learn more through the awesome EdgeDB documentation. There is also an active and engaged EdgeDB community on Discord.
Happy coding!
P.S. If you liked this post, subscribe to our JavaScript Sorcery list for a monthly deep dive into more magical JavaScript tips and tricks.
P.P.S. If you need an APM for your Node.js app, go and check out the AppSignal APM for Node.js.
{kind=link}